
The problem that I want to discuss in this note hunted me in the context of my migration to the GNU/Linux desktop. This transition happened not so long ago. In 2004 I was still working on a Win98SE desktop. With lots of GNU on it, it is true. I switched to a GNU/Linux desktop in the spring of 2005.
My work is very text-centric. From this perspective, the GNU/Linux desktop is definitely superior. But some things seemed to miss. How can you recognize the characters in the image of a text? I tried some open-source solutions, but they all seemed to be at the level of interesting experiments. And how can you put text behind the image of a text? A DjVu image, for example.
From time to time, I did ask the Google search engine to find some information about adding text to a DjVu image with open-source tools. For three years nothing came up. I almost gave up this kind of search.
Recently however, I stumbled upon a post on a blog. The post explained concisely how to use Tesseract, Perl and djvused for the insertion of OCRed text into DjVu. The blog opened the door to an unseen world.
It should be stressed once again that the whole point is to use only GPLed tools for the insertion of text behind DjVu. I did not try the commercial version of DjVu, but I understand that it does add OCRed text. There are also commercial tools for the insertion of OCRed text in PDF. Here I am not talking about this.
In order to replicate the experiment outlined in this note you have to look at the other notes on DjVu as e-book, pdf2djvu, text behind a manuscript, OCRed text, Tesseract and the Tesseract Box Editor.
Should you work on a GNU/Linux desktop? I did my experiments on such a desktop (a Fedora 7 operating system with Gnome). I think, however, that with some adaptations all this would function in Windows and probably quite easily on Mac OS X, which is a Unix-based operating system. All you need is DjVu, Tesseract, Python, ImageMagick and some knowledge of the commandline (the MS-DOS Prompt in the Windows world).
The first thing you should do is to start with a new, empty folder. The next thing to be done is to open a console and change the current directory to the empty folder, the working-place. We need a clean working-place because the scripts that we are going to use will process all the files of a certain type in that folder. Thus, if you work in a folder already populated with files, you might lose precious data.
In fact, the first files that we need on the working-place are the tiff files corresponding to the pages of the e-text. I will use a somewhat artificial example. In my case, I will make a copy on the working-place of a paper of mine. The source of the paper was written in LATEX and compiled into a pdf. The pdf has, of course, the text in it, not just the images of the pages. But, for all practical purposes, the process would be similar in the case of scanned pages of the printed version of my paper.
Now I am going to convert the pages of the paper into tiff files. The details of the procedure are not so important here, but I will sketch it, because the reader might also want to work with a pdf file. Anyway, for the first tests choose a small one. Working with a large pdf takes a long time. A ten page pdf with no colors, no images and columns, just with text, is the ideal file for tests.
In the first step, I split the pdf into individual pages with pdftk:
pdftk name-of-the-file.pdf burst
Then I have used the script pdf2tif (you find it in the archive - I refer here to the first version of the scripts, from 30 december 2008; see also the downloads ■ section). The script is for GNU/Linux. And what about Windows? The tools invoked in the script are available on Windows. The convert utility is part of ImageMagick. As for the other tools, when I worked under Windows, I found very useful the GnuWin32 tools. As for the for-loop in the script, it should be easy to replicate it under the MS-DOS console. You do not really need Bash.
Another question under Windows: how can you read all those script files? They are just plain text files. Use Vim or another real text editor to read them.
It is important however to rename the tiff files, in case they are not listed in the order of the corresponding pages. Names such as 001.tif, 002.tif, 003.tif and so on are OK as long as you do not have more than one thousand pages in the e-book.
Summing up, what is important at the end of this first phase is to have an ordered collection of tiff files. They might be scanned pages. They might be converted pdf pages or they might be extracted from a djvu file and so on.
If you already have the djvu file without hidden text, just skip this section. In all other cases you have to build a DjVu e-book.
In my example, it is interesting to build two djvu files. The first is build using pdf2djvu and this file will contain the hidden text already present in the pdf (from the LATEX source). The second is build from the tiff files. We will insert OCRed text in this second file and then compare the results with the first file. Thus we have a possibility to control the working of the automatic insertion of hidden text into the second file.
Is it possible to build the DjVu e-text directly from the tiff files? Yes, if they are bitonal. This is exactly the case in our example.
I used the tif2djv script for the generation of an e-text.djvu file combining together all the djvu files corresponding to individual pages. I included this script in the first version of the downloadable archives (see the downloads ■ section). The script as such is not essential. What is important is to keep in mind that I have named this djvu version of my paper e-text.djvu. This name, “e-text”, will be used by the (first version of the) script which inserts automatically the OCRed text into DjVu.
The note on adding OCR to djvu file, from which I learned about Tesseract OCR and the technique of inserting OCRed text into DjVu, contained a Perl script for the automatic inclusion of hidden text in DjVu. That script uses both the txt and the box files created by the OCR program.
Remember that OCR means Optical Character Recognition! The program does not “read” the text. It just divides the area of the text in boxes. Each character ends up in a box and in the box file one can find the coordinates of these boxes. Each character is treated as a small picture drawn in the respective box. The program associates to each picture a code, the code of a character.
In the text file, the OCR program puts lines of text, not the coordinates of the boxes. The information is however useful, because we know where lines and words start and stop.
One idea would be to take words from the text file and extract the coordinates of the box surrounding the word. Remember that the box file gives us just the coordinates of each character! In a first attempt, I followed this strategy and I have written in Python a script which needs as argument the box file, but also needs the corresponding txt file. I include here just for the curious that initial script.
There was however a problem. What happens when I correct the box file with the Box Editor? Well, I do not want to train the OCR; I just want to correct mistakes. But doing this only in the box file makes the txt file unusable for the Python script.
Thus, I took the decision to rewrite the Python script and use only the box file. The idea is to guess from the coordinates the location of the lines and of the words on the page.
The next phase is very important. You need Tesseract OCR.
For reasons that I have explained in the above digression, I have generated only the box files. I will not explain in detail the procedure. Have a look at the ron-tess.sh script in the first version of the downloadable archive.
Remember that ron-tess.sh contains commands appropriate for the Romanian language (i.e. for the printed letters in a Romanian text). In the case of other languages, you have to adapt the script.
Tesseract OCR adds automatically a txt extension to the name of the box file. You have to change the extension to box.
The most important thing is that for each name-of-the-file.tif the corresponding box must be name-of-the-file.box. It is not difficult to understand the reason if you study the scripts used here. Anyway, this way of naming the files keeps them in order.
Cătălin Frâncu has written a Tesseract Box Editor for training the Tesseract OCR. Working with the Box Editor, I noticed that it could be very useful for adding text to djvu files. See more information on the note about the Box Editor.
You can use both the modified and the unmodified form of the Box Editor for the correction of the box files. In the automatic process you do not copy and paste by hand the coordinates of the boxes. Just remember to save your work before closing the Box Editor! It does not save the corrections automatically and it does not tell you that you are closing without saving. You are responsable for what you are doing.
As an illustration, I will add an image with the third page of my paper, as it appears in the Box Editor.
In the figure, even if you do not know Romanian, you can see that the characters have been recognized for large sections of the text in Romanian. The Greek text has not been recognized at all. This is not a surprise.
For the content of the fragment in Ancient Greek see this excellent page by Egon Gottwein.
How we correct the boxes and their content? The figure gives you an idea.
In the figure, the box around the hyphen was too short. I made it longer. Otherwise, the Box Editor and the box2dsed.py script will see two separated blocks of text (not two words united in one block).
What about the Greek text? Is it possible to repair it too? Yes, just put the correct letters. See this note on typing Ancient Greek for the details. I have inserted Betacode in the boxes with the Box Editor, then I have converted, in the box file, the Betacode to Unicode. Please note that, in Vim, it is possible to select a vertical region (a column of Betacode signs, in this case).
Download ■ the archive with scripts (first version) and put it in a safe place. Extract to the working-place the scripts box2dsed.py and txt-in-djvu.sh; these are the scripts you are going to need for adding text to the djvu file.
In the terminal, type
./txt-in-djvu.sh
and press Enter.
Of course, this will work only under GNU/Linux in this simple manner.
Under Windows you need Python (because box2dsed.py is written in Python) and you have to adapt txt-in-djvu.sh, which is a Bash script (the equivalent in Windows would be a bat file). I will describe briefly what does the last script.
First, the script creates a file named e-text.dsed with the following content:
select; remove-txt
Then, in a for-loop, each box file is processed with a command
python box2dsed.py name-of-the-file.box
The Python script generates a temporary file with the same name as the tif and the box file, but with the extension “psed”. The content of these files is added succesively to e-text.dsed.
The final command insterts the text:
djvused e-text.djvu -f e-text.dsed -s
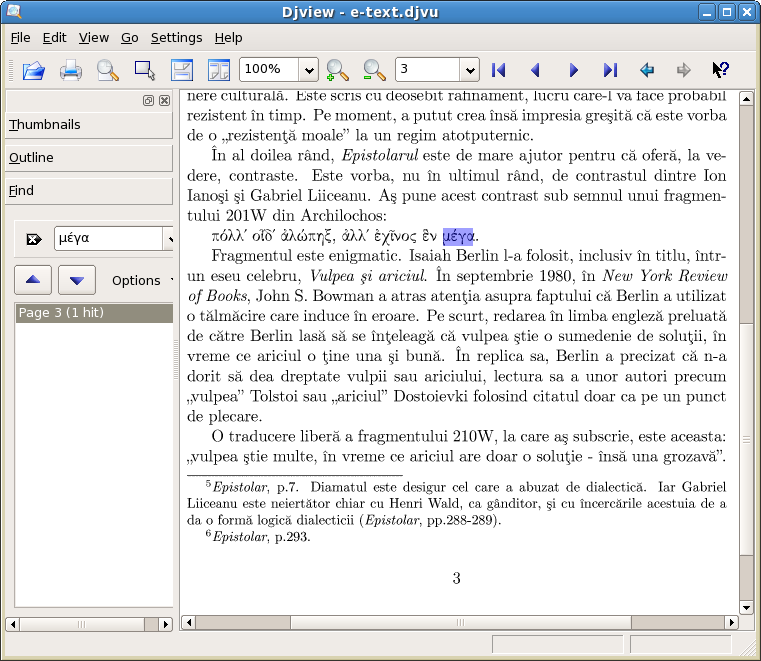
I repaired the Greek text with the Box Editor and Vim, as I had explained above. As you can see in the image, I can now find a Greek word in the text.
Judging from a practical point of view, the result is pretty good: we have now the possibility to search the text. The defects of the OCRed text are, so to speak, “covered” by the image. We read the image of the printed text, not the hidden text.
How accurate is the entire process? Not entirely accurate. There are many differences between the LATEX -based version and the OCRed version. Their number is however balanced by the fact that many of the differences are very small.
I have extracted the hidden text from the djvu created with pdf2djvu (where the hidden text is based upon the LATEX source) and the OCRed text inserted automatically. In the image, on the left is the LATEX -based text and on the right is the OCRed text. The numerical codes for characters are inserted by djvused.

In the image, it is the text hidden on the second page of the paper. The boxes and their content created by Tesseract has not been edited. There was no manual intervention on this page.
As you can see, in the figure, there is a line highlighted in yellow. While the corresponding line on the left has the code for an opening Romanian-style inverted comma, on the highlited line you can see two commas. This is a systematic mistake, stemming from Tesseract. It does create problems for the automatic insertion of text, because one would expect a single comma (after a word).
Another frequent problem was caused by LATEX ligatures. For example, the group “fi” is elegantly rendered by LATEX with a ligature. Tesseract is confused by the ligature. I mend by hand such errors.
An interesting problem is caused by a superscripted number and a successive period or comma. Tesseract draws small boxes around the superscript and the period or the comma. The vertical distance between these boxes is similar to the distance between lines. I had to take a decision in the script for the automatic insertion of text. I raised the boxes around periods and commas, in order to make them as tall as the preceding box.
Sometimes, however, the combination of pdflatex and pdf2djvu leads to a mistake.

Both methods do not reconstruct hyphenated words at the end of lines. Thus, counting words in the hidden text is a problematic operation.
Finally, I would like to add an observation on the advantages of open-source and open-access. Even in the case of files, open access is crucial. A binary, cryptic or even deliberately encrypted file might create false impressions. For example, it would be difficult to know what happens with hyphenated words in hidden text.
Some people might wonder why I have kept so many scripts? Why not bundle everything together in a program, start it, open a file, press a button and get the final result?
Well, at least for this note I found more appropriate a description of each step (see the observation above on open-sources and open-access). And I offered for each step a small, easy to analyze set of commads.
You are free to combine all the above steps. I do not see however the advantages of such a procedure.
At least with the OCR, there is one big problem. You must correct the results in the box files. You may do this directly in the final djvu file, but you may want to have some control on the way on what is going on.
In practice, I have encountered other bottlenecks too. Sometimes, the pages of a pdf are defective. On other occasions, it is difficult to generate useful tiff files and so on. Each time, you must find a solution which is more or less ad hoc.
What is really automated is the insertion of the coordinates in the djvused script. To do this manually is really time-consuming, tedious work.
On Google Code I found a package for the Fraktur script. We call this kind of script, in Romanian, “scriere gotică”.
It was not difficult to package the archive as an RPM and install it on Fedora 7. The problem was that the Fraktur “language” generated boxes with several characters on the first field. The first version of the Python script, described above, assumes that there is only one character on the first field (and some Tesseract mark-up, which is cleaned).
The second version of the Python script attempts to work with boxes with several characters on the first field.
Empty boxes generate an error, but this is normal. There are some other box files which, for reasons that escape to me, also generate errors. Cleaning them manually will probably eliminate the errors. I hope there are not too many such box files!
Tesseract recognizes hyphenated words as distinct chunks of symbols on paper.
I tried to reconstruct automatically hyphenated words. This improves the efficiency of the searches in the djvu file.
Tesseract does not recognize columns or facing pages. This is not dramatic if you do not need a text file. If you use the text behind djvu, Tesseract's results are quite useful, because you search words and read the image (not the text behind the image!).
A solution to the multiple pages problem is to cut the tif file. The split-tif script (from the 2009-01-30 archive) attempts to do this.
You have to insert in split-tif the adequate numbers however!!! The script id-tif generates useful information concerning the geometry of the tif file.
Be very cautious!
rm $tiffile
deletes the original tif files! Keep this line commented (with a sharp sign at the beginning)! Test first and only if you think that the script works correctly, delete the original files.
The most pleasant discovery during the experiments with the insertion of text behind djvu was the Tesseract Language Pack for Ancient Greek. It has been created by Federico Boschetti and you will find it on his page with Greek and Latin digital tools.
Working with Boschetti's package I realized that I do not have on Fedora 7 a convenient keyboard for Ancient Greek. I improvised one (see this note).

The results need to be revised manually, but this is a far cry from the attempt to write the content of the boxes from scratch.

The hit on the first page (see the image) is on a portion that was not cleaned manually. On the second page I did some corrections, as shown above, with the Tesseract Box Editor.
The case of the Ancient Greek text illustrates the basic feature of the insertion of text behind djvu: errors in the OCRed text are compensated by the fact that we read the image and we gain a lot because we can search/guess which portions of the image of the text do interest us.
Be very careful when you work with this scripts! There is no explicit or implicit warranty.
First test! Work only with copies of the image files. Improper use or bugs in the scripts will almost certainly destroy precious data.

The 2009-01-30 version of the scripts uses “ebook” as a generic name for the e-text.
More important, the scripts work with boxes that have several characters (without spaces !) on the first field of the box file.
An empty box file will generate an error. This does not affect the work of the scripts, but it is recommended to rename an empty box file (.box.nul, for example, might be its extension).
The Python scripts attempts to reconstruct hyphenated words. However, if the hyphented word is on different pages, it remains broken. Also, this reconstruction does not work on pages with two or more columns.
The script box2dsed-Fraktur.py does work with Fraktur, but it does not reconstruct hyphenated words.

In the 2008-12-30 archive you will find the first version of the scripts. They work only with box files that have exactly one character on the first field.