DEX online is a vast collection of definitions from various Romanian dictionaries. As its name suggests it is available online. For other information concerning Romanian dictionaries see the note here.
There are several dictionary shells created especially for DEX online. There is a list of these applications and of their characteristics on the DEX online site. I have written a note about a Qt-based dictionary shell for DEX online.
I explore here the other possibility: to use an existing dictionary shell and adapt the DEX online database to this shell (create a version of the dictionary for the shell, not the other way round). I have tested this possibility for StarDict (see my note about StarDict).
If you are just interested in the use of the dictionary, you may jump to the section about usage ■. Have a look at the image with explanations of StarDict's usage with DEX online ■.
Those interested only by the Windows platform should consult the note on the adaptation of DEX online for StarDict on Windows.
The first thing you need is the database. You may obtain it - as an SQL dump - from the DEX online site. Please note that these notes concern the database as it was at the beginning of 2010. In August 2010, the database is different. The scripts used in January do not work with the new database. They have to be rewritten.
You must read first the license of the database. The database is copyrighted (C) by DEX online. The copyright is GPL. This means that you may use the database, but you have to offer its content also under GPL and you also have to mention the copyright of DEX online. Please note that changes in the license might mean that only portions of the database can be extracted. The scripts which I discuss later offer you the possibility to select only the definitions from some of the dictionaries.
Working with the database, I realized that it is a sort of golden mine. It has all the qualities and all the problems of a mine. The kernel of the lexical records in the database is a definition. The record tells you from what dictionary it has been extracted and this is basically all the information explicitely available for linguistic researches. (There is also a machinery for the morphological variations of the Romanian words.) There is no network of connections between the lexical units or some similar structure that could be used in linguistic researches. However, one could mine (in the sense used in “data mining”) the huge material. This is not my ambition here. I just show how you can bypass MySQL. This does not mean that you should bypass MySQL or some similar tool.
The procedures described here try to show some aspects of the extraction of a source for a dictionary which can be used with StarDict. Please note two things: these are working notes (no claim of clarity!); you must be familiar with GNU/Linux, a bit of MySQL, a bit of Python, regular expressions and the Vim programming editor. The scripts are under GPL. You may not use them in closed-source software.
The database that I have used (at the beginning of 2010) is quite large. When you unarchive it you get a rather large file of over 384 MB.
As I have said, the database is an SQL dump and it can be used with MySQL. This is the basic intention of the DEX online team headed by Cătălin Frâncu.
You can install the software machinery for searches and other operations with the database on your local computer. You may read more about the DEX online code on the DEX online site.
The SQL dump is from MySQL. How can you however bypass MySQL? The idea in these experiments is to treat the SQL dump as a huge text file. It is shown how one can extract a source for the StarDict toolchain.
The basic structures that we find in the SQL dump are a series of tables. Each table has fields (the columns, if you like this way of talking) and records (rows with values for each field). Now, these tables could be extracted and arranged in the CSV format. Basically a CSV file is a text file in which each row is a record from the table. The values are separated by commas (hence the name C(comma)S(eparated)V(values)).
By all means, the most interesting table is the table which contains the lexical definitions. It has eleven fields. I will describe briefly some of the fields.
The first is the (unique) Id for each record (each lexical definition). I will call it also the “definition number”. In databases these unique numbers are very important when you have to make correlations among tables.
The third field contains the Id of the source (the dictionary from which the definition has been extracted).
The fourth field in the definition is called “lexicon”. The DEX online documentation explains that this is: “A bit of text extracted from the beginning of the definition. This is usually, though not always, equal to the term being defined. It is not used for searching, but only for sorting definitions” (see schema.txt in the documentation). I will also call it the “definition label”.
The sixth field contains the definition in text format. It has markup that can be converted into something similar to the markup used by the ReStructuredText format, for example.
The seventh field contains the definition in HTML format.
The eighth field indicates the status of the definition. It is very important for the filtering of the definitions. DEX online works like a forum. Everybody quotes definitions from dictionaries, but sometimes spammers dump garbage into the forum.
In the downloads section below ■, you will find - in the stardex-tools kit - a Python program named “sql4dic.py”. Let's suppose that dex.sql is the MySQL dump you got from DEX online. You have to put the tools and the MySQL dump in an empty, specially created folder (e.g. stardex-workshop). This is necessary because there will be a lot of auxiliary files. And always work with copies! It's an elementary precaution.
In the folder stardex-workshop, you can call sql4dic.py (under GNU/Linux !) like this (in a console; see this note for details):
./sql4dic.py dex.sql
You need Python, Vim (or some other compatible programming editor), grep, sed, GNU sort and, of course, bash in order to use the stardex-tools. I have tested the tools under Fedora 10, which is a GNU/Linux distribution. I have no idea how they might work (or not work) on another platform.
The above command will create a dex.baby, a dex.csv and a tmp-nonstd.csv file. Let's ignore for the moment the “baby” and concentrate on the CSV files.
The main csv file is, of course, dex.csv. It should be easy to inspect dex.csv with Vim, if the computer has enough resources (1-2 GiB memory, at least a similar swap and a reasonably fast CPU). The Python program has extracted the CSV file from the definition table in the SQL dump. It uses the csv Python module in order to open and process the CSV file.
The tmp-nonstd.csv contains the lines which do not have the standard number of fields (eleven fields). There should be a limited number of such lines. You get a message on the console when the program finds such lines.
The dex.csv and tmp-nonstd.csv are auxiliary files. You may delete them when you do not need them anymore.
Another table included in the SQL dump (properly speaking, the dump contains the SQL commands for structuring and populating the table, not the table as such) is the lexems table. According to the DEX online documentation: “A lexem is essentially a word. Homonyms get separate lexems each.”. The stardex-tools do not use the lexems table directly. Instead, they use the “LexemDefinitionMap”.
Now, use on the command-line this call:
./sql4lex.py dex.sql
If everything goes well, you get a dex-lex.csv file. This file contains two fields. On the first field are definition numbers. On the second field there are lexem numbers.
A lexem may have different forms. In DEX online, this reflects the morphology of the Romanian language. When you use, on the command-line, the next call
./sql4wl.py dex.sql
This will create a dex-wl.csv file. In this file, on the first field are lexem numbers. On the second field, there various forms corresponding to lexems. The “wl” suggests that this is essentially a word list.
Summing up, the three Python programs with a “4” in their name are for the creation from the SQL dump of CSV files: a file with definitions, a file with correlations between definitions numbers and lexem numbers and a file with lexem numbers and the various (morphologically different) word forms corresponding to them.
Before going on, we should further clarify the terminology that we use here. The StarDict source is made up of dictionary entries. Each entry is a pair of two elements: the element used for searches and the content (the content of an article of the dictionary). Let us call the first element of the pair a “searchword”. A searchword might be a word or a phrase.
Now, the content of the entry (the second element of the pair in a dictionary entry) has a head that is called “headword”. This headword is usually emphasized (using, for example, a bold font).
In the example presented in the note on StarDict, we have used a tabfile. In a tabfile each entry is on a single line and the searchword and the content are separated by a tab. Here we will use another type of source for StarDict dictionaries: the babylon file.
A babylon file is a text file with the following structure. In a babylon file, each entry is written on two lines and is followed by a blank line. Thus a blank line has a precise meaning in such a file! On the first line is the searchword. On the second line you have to put the content of the dictionary article.
The baby file created by sql4dic.py - as explained above - is a babylon file. We could ignore or simply remove the dex.csv file. It is only used for the creation of the baby file.
The baby file uses as searchword the definition labels. This is both an advantage and a problem, as we will see in what follows.
For the moment, it is interesting that we can call the stardict-editor and build a dictionary directly from the baby file. In the Compile panel of the StarDict-Editor you have to choose Babylon file (instead of Tab file). The rest of the process goes on as explained in the note on the StarDict toolchain.
Older versions of StarDict had two limitations. They had no HTML engine and they could not handle dictionaries with entries having the same searchword.
In order to create a text version of the dictionary, sql4dic.py has to be modified. I will mention here only two important modifications.
First, for the definitions one must use the sixth field from the DEX online definition table. This means that for the text format one uses the InternalRep field
Second, one has to convert somehow the text markup.
In the figure showing a search with StarDict 2.4.5 there is a hint to the other problem of older StarDict. It does not have support for entries with the same searchword. This is especially a problem in the case of DEX online. DEX online is a collection of dictionary articles from a series of dictionaries. Inevitably, there will be several articles having “libertate” as searchword and so on.
The solution to this problem is to build separate StarDict dictionaries for each of the DEX online sources. Again sql4dic.py has to be modified. In it there is a function este_art_ok(). This function has one argument: a line from dex.csv; it examines the number of fields and the status. One has to add also the condition that the third field has a certain value. For example, if it is “1”, then only definitions from DEX98 are selected.
The separation of the dictionaries is especially useful for the work with the command-line version of StarDict.

The tools in the January 2010 download create by default a dictionary in HTML format. A version of the dictionary is also available for download.
The dictionary in HTML format has been tested with StarDict 3.0.1 under GNU/Linux.
In the following sections the discussion is about the dictionary in HTML format.
Why are there in the stardex-tools kit five tools and not just one? Well, the answer is that it is prudent to check by hand after each step the results. Some retouching also has to be done by hand.
One file that is not generated by a program is nonstd.baby. You have to create it by hand from tmp-nonstd.csv.
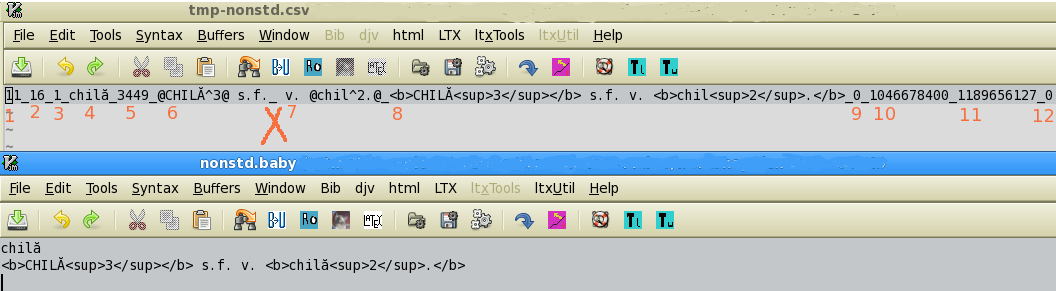
The file tmp-nonstd.csv uses the underscore as separator (not comma). I took this decision in order to have a better view of the fields. Commas are difficult to spot.
The example in the figure is artificial. The real examples that I have found were a bit longer and more intricate. However, one can see which is the problem: there are 12 fields. I have put numbers under each of them. The spot where there should be no separator is marked by an X.
Vim is very useful for retouching. You can see in the figure how you can transform XML entities into UTF-8 characters (which are used by StarDict).
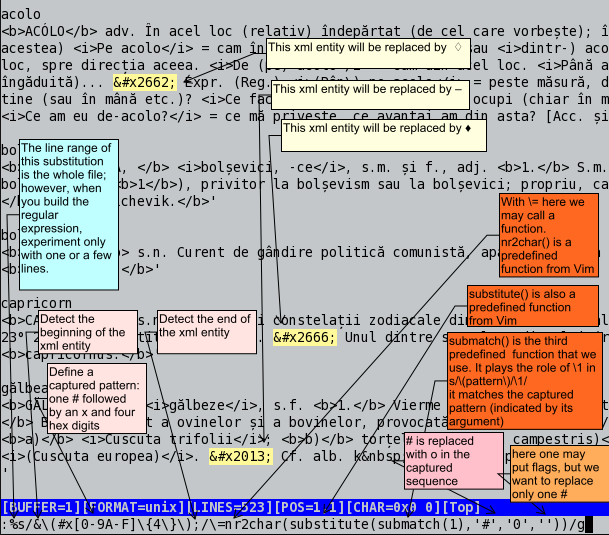
In other situations, we might retouch the source because we want the dictionary to have a better appearance. And sometimes decisions have to take into account the meaning of the text.
The content of the nonstd.baby file is added to the dex.baby file with the help of a bash script, invoked like this:
./add2baby.sh dex.baby
The bash script also contains some substitutions. You need sed in order to make those substitutions.
If you just want to make the substitutions you need a dummy nonstd.baby file (with the size 0).
Most of the substitutions are commented. They have to be uncommented before use. Of course, they might be risky. Work with copies!
The babylon format of the StarDict source has a nice feature. The searchword may have alternatives. The alternatives are indexed by the StarDict editor in a syn file. The name of the file suggests “synonyms”, but the alternatives in the searchword might be used for storing grammatical forms. Each form will point to the same entry as the head of the searchword.
In order to create searchwords with alternatives, one has to modify a bit sql4dic.py; the change is explained in the figure.
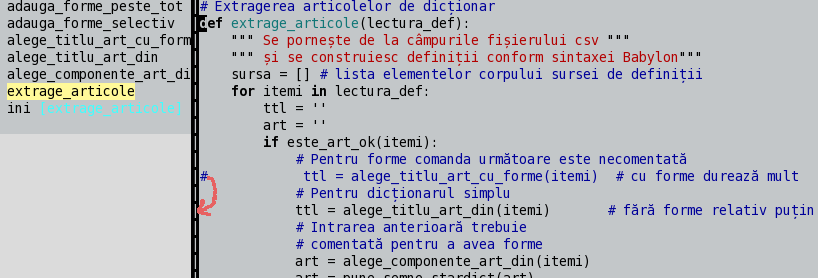
The red arrow in the figure shows how one line is uncommented and another line is commented. I use TagList as a source code browser in Vim. It helps to find the function extrage_articole(), where the change must be operated.
I tried first to use the possibilities of the Python csv module for search. I gave up because I realized that I do not know how to optimize the code. Everybody must recognize his limits.
I resorted to grep for searches. I find grep a wonderful tool and Python has the possibility to invoke external commands.
If you give grep a definition number, it will search for the corresponding lexem numbers. Then you can look in the word list for the forms associated with those lexem numbers and add them as alternatives in the searchword.
In order to add the grammatical forms you need to extract first the dex-lex.csv and dex-wl.csv files. Only after this you can use the command
./sql4dic.py dex.sql
This time the Python program will need a much longer time. I tried first to use an external temporary file and the execution of the program ended after 24 hours.
The next time I used pipes. The GNU/Linux system and Python proved their robustness and did not fail and the process ended after 18 hours.
However, there is a problem with the size of the dictionary when you attach forms to every searchword. The source has 100.8 MB and, even after compression, the dictionary is still bulky. The syn file is big and the references it provides are a bit confusing.
I took the decision to add alternatives only to entries which quote DEX98. This should be enough for practical purposes. The source dropped to 71.5 MB, but the effect on the syn file was substantial. The processing time was reduced to three hours and ten minutes (which might be less on a faster machine). I thought that this is reasonable for this type of processing (which is performed rarely).
Let us now recapitulate. You can create a dictionary for StarDict using only the table with lexical definitions from the SQL dump. Definition labels are used as searchwords. This is not that inefficient as it might first seem because StarDict is able to execute fuzzy searches or look up in the whole dictionary.
Then, with the help of the lexem map and the word list, one can add grammatical forms. After the addition of grammatical forms, the searches in the resulting dictionary are quite efficient.
There is however a problem: the searches in the StarDict graphical interface do not look very attractive. Definition labels pop up on the left panel (which displays a list of searchwords) and, far worse, are used as titles on the main panel. Thus you may get “alexandrumacedon” as a title. Casual users would get very confused.
The following command generates from a baby file a babylon file:
./src2bab.py dex.baby
The src2bab.py transforms the raw source into a babylon file with searchwords that can be displayed. It replaces the definition labels with the headwords of the entry's content. Grammatical forms are not affected.
There are several problems with this procedure. The DEX online project has kept intact the initial forms of the definitions as one finds them in the printed dictionaries. The dictionaries do have a roughly similar structure, but they have no regular form. The most striking problem is with NODEX which has confusing headwords. In this dictionary the bold font at the beginning of the definition includes sometimes a grammatical form or even the digit “1” (for the first meaning of the word).
For some dictionaries you have to take a decision in the case of idiomatic expressions. StarDict could use them as searchwords, but this is not very helpful. For example, if you look for “cooperativa ochiul şi timpanul” (a slang expression designating the former communist secret police) on the Internet version of DEX online you will get no hit. You get one however when you look up “cooperativa” or “ochi” or “timpan”. You also get a hit if you tick the box for search in the whole text of the dictionary.
Another problem is that the internal cross-references of StarDict get broken. These references use HTML hyperlinks with “bword://” instead of “http://”. They point to lexems, but these have the same graphical structure as the definition labels (all lower case and no spaces between words). “Organizaţia Naţiunilor Unite” is “organizaţianaţiunilorunite”.
I have left for the retouch by hand most of the problems mentioned above.
Now a final touch that you can add to the babylon source is to add to it the content of a supliment.babylon file. You can put there any supplementary definitions that you have created directly in the babylon format. It might be convenient to use the command
./add2bab.sh dex.babylon
The supliment.babylon file might be used as an update of the source. Each definition in DEX online has a timestamp (for creation and modification). As shown in the figure, Python can work with these timestamps.
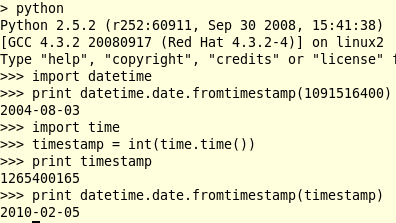
As in the case of the sources of the dictionaries, a condition can filter all the definitions according to their timestamp.
After the compilation with the StarDict editor, it seems to make sense to use the command
./add2ifo.sh dex.ifo
You may tailor the bash script add2ifo to your needs. The script included in the January 2010 download just changes the version of the dictionary. The change works with StarDict 3.0.1.
I suppose that most people who read this note will just install the dictionary in StarDict and give it a try. Therefore it makes sense to offer a few explanations concerning the use of the DEX online version for StarDict. First have a look at the “Usage” figure; it gives basic orientations for the use of the graphical interface of StarDict.
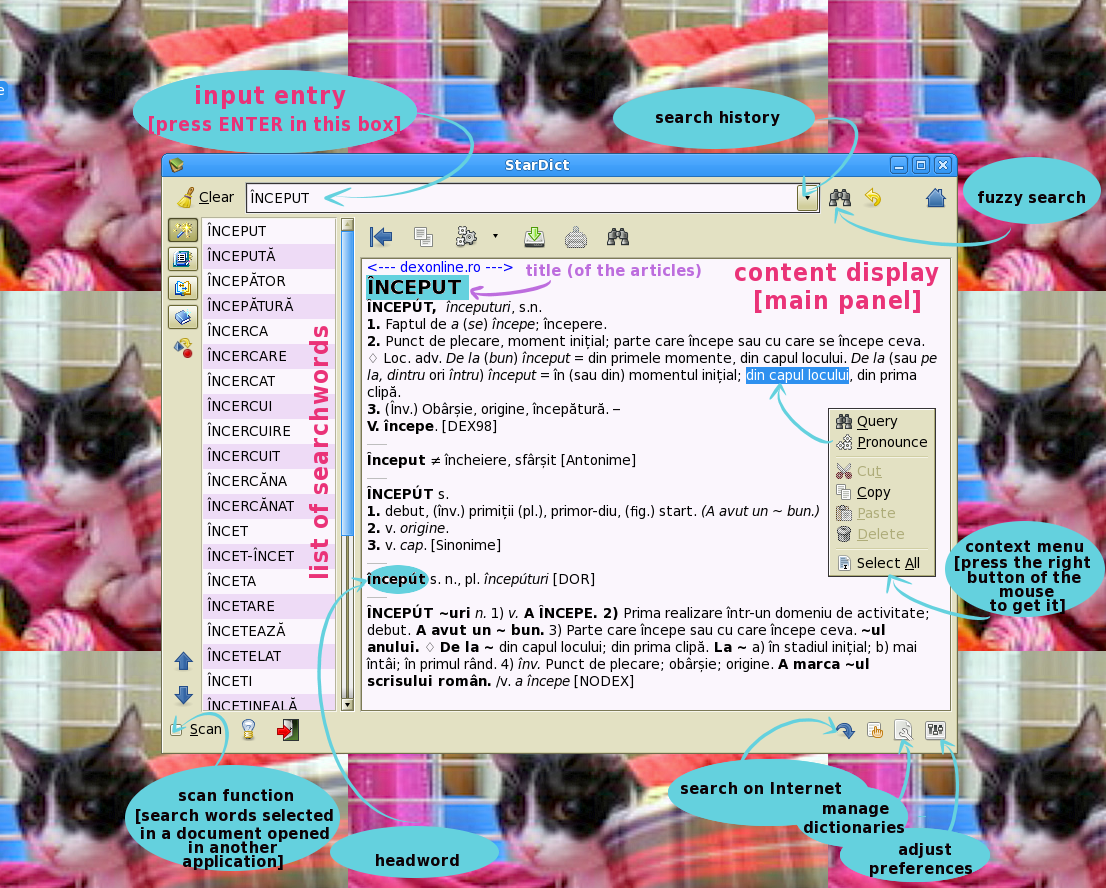
In StarDict, searches are case-sensitive. Sinonime will give a different result from sinonime.
The all-uppercase searchwords are identical or are extracted from the headwords of the entry towards which they point. The lower-case searchwords are grammatical forms of some word. Thus “AVUT” points to entries with this headword, while “avut” points to the verb a avea.
StarDict 3.0.1 displays in the main panel the content of all the entries which share a searchword (not the headword, because different sources have different styles for the headword!).
A very important feature of StarDict for many users is the capacity to look up words from documents opened in various applications. For this you have to activate the scan function in StarDict.
There might be a series of questions concerning the use.
I opened a page in Firefox. Why cannot StarDict find certain words? DEX online uses comma under s and t as a diacritical mark. The Romanian Wikipedia uses cedilla. The figure indicates a solution.
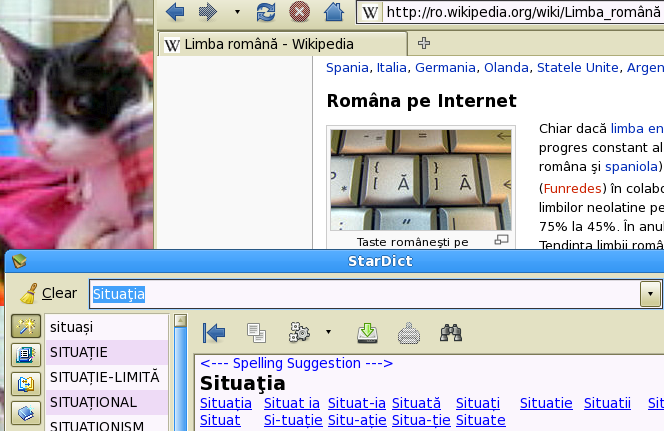
I was very disappointed first by the disaster caused by cedillas. Then I activated the spelling suggestions for Romanian in StarDict. It worked like magic.
For the use of the speller read the note on Aspell. StarDict is able however to use other spellers, not only aspell.
Is it possible to look up a word on the DEX online site? You have to adjust the preferences for website search in StarDict as shown in the figure.
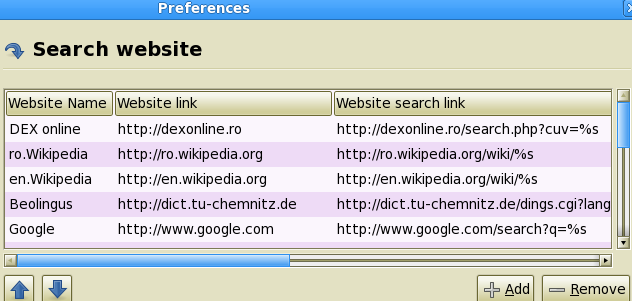
The result is the ability to use both the local version of DEX online and its Internet version. Using StarDict scan function you can also search on the DEX online site words that you cannot find in the local version of the dictionary.
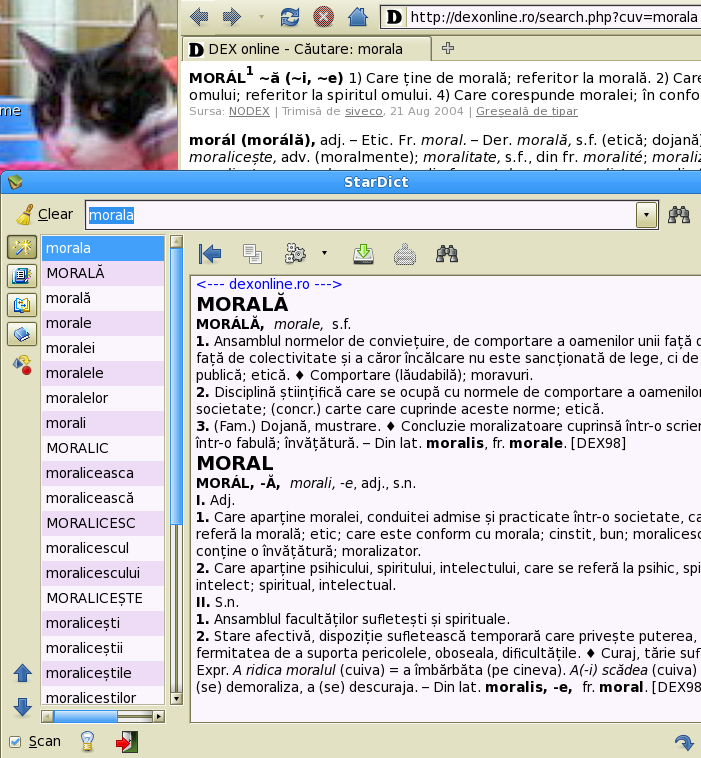
At the end of the definitions there is an abbreviation. How I make sense of it? Click on the abbreviation to select it (or select with the mouse). Then press the right button of the mouse and get the context menu. Choose “Query”.

May I click on the blue dexonline.ro heading in the main panel? Yes. You will get information about the DEX online project and the license of the electronic version of the lexical definitions.
The main disadvantage is that the database is not constantly updated. In order to update the dictionary you have to recompile it from an updated source.
There is - as far as I can see - no solution in StarDict for the display of morphological tables (declinations, conjugations). Unlike the interface of the dictionnaire-le-littre, StarDict has no function for the display of morphological tables.
DEX online is also a forum. The local copy of the dictionary has no forum functions.
However, the StarDict version has a series of advantages.
StarDict is able to search in the whole corpus of definitions. Let us say that we write in the input entry:
|Tiktin
The vertical bar is important! It tells StarDict to use a full-text search. You get all the entries which have in their content Tiktin's name.
It is possible to use regular expressions in StarDict's input entry box. For example,
:^.*(ţie|DAŢIE)$
will get grammatical forms which end in “ţie” and searchwords which end in “DAŢIE”.
Sometimes, a fuzzy query may work as a kind of substitute in case you want to find only words within the limits of the Levenshtein distance (see the section ■ about fuzzy queries from the input entry box).
StarDict uses the Levenshtein distance for finding the searchwords which are close to the input. (See Michael Gilleland's Levenshtein Distance, in Three Flavors for an essay on this topic.)
Using this capacity of StarDict one can obtain a list of searchwords which approximately match the input (see an example in the image).
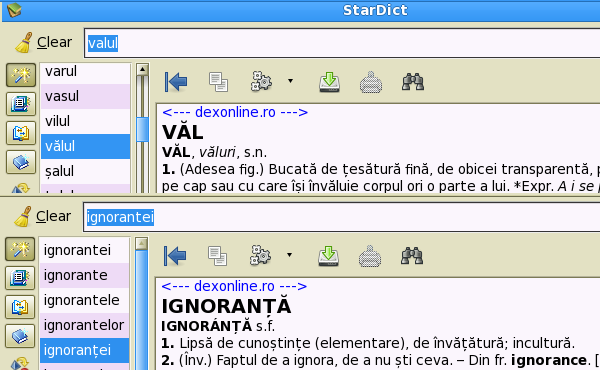
In the figure is illustrated the following situation: let's suppose that someone has written “valul ignorantei” (no diacritical marks!). This has a meaning in Romanian (the wave of the ignorant woman or even the wall (Roman vallum) built by an ignorant woman), but probably it would not make much sense in the context. The figure shows how we can use the Levenshtein distance; we try to find words at a few edits distance from “valul” and ”ignorantei” (in StarDict, the maximal value of the Levenshtein distance is 3). Both words are grammatical variations, thus we search them in small case and then we use the fuzzy search. The results are still ambiguous: “valul” could be “vălul”; “ignorantei” could still be an ignorant woman wearing a veal, but the most probable choice is “ignoranţei”. The phrase the veal of ignorance is a well-known philosophical expression.
There is a moral to this story: don't write without diacritical marks! The Romanian text becomes ambiguous and it is beyond the present-day power of a computer program to figure out if you are a philosopher writing about the veil of ignorance or just somebody saying that some ignorant person wears a veil.
It is possible to call the fuzzy search from the input entry box. You have to start the input string with a slash.
It is possible to put some character which does not exist in the searchwords and combine in this way an immitation a patterned search with a fuzzy search. For example,
/*val*
will get you such words as “ovale” or “evaluai”.
Note that pressing the “Fuzzy Query” button leads to different results, when you remove the slash from the beginning of the input entry string. It becomes just a “glob-style pattern matching”. It is also similar to the :.*val.* search (which uses a regular expression).
You can get suggestions if you enable the virtual dictionary “Spelling Suggestion”. Put it in the group where the DEX online is included!
See the note on StarDict for the explanation of the Spell Check plugin.
You may also wish to consider the note on Romanian dictionaries for GNU Aspell.
The spelling suggestions are useful when the input lacks diacritical marks.
The fuzzy search is also helpful
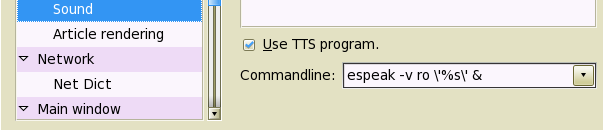
StarDict has several ways of pronouncing the words from the dictionary.
I find most convenient the setting for sound preferences explained in the note about StarDict.
The figure illustrates a setting which makes possible the pronunciation of a sequence of selected words.
After the selection of text, call the context menu. Press “Pronounce”. See also the “Usage” figure above ■.
Grammatical forms are included as alternatives to searchwords which point to the definitions quoted from DEX98.
Let us say that you input “meargă”. In the list of searchwords you will see “meargă” - written with lower-case letters - on top of the list. In the main panel it is displayed the content of the article entitled “MERGE”, because “meargă” is an alternative to the main searchword “MERGE”.
How can you get the corresponding articles from all the dictionaries? Click and select the title (in this case, “MERGE”). Then call the context menu and press “Query”. If you have the scan function enabled, a floating window will appear after the selection.
What happens if I press the headword (not the title)? Headwords usually have accents. You will have to select an option from the suggestions. Thus it is safer and quicker to select the title, not the headword.
It is possible to add a morphological dictionary to the Romanian group of dictionaries.
The morphological information is extracted from the DEX online database. There is no attempt to correct it by hand.
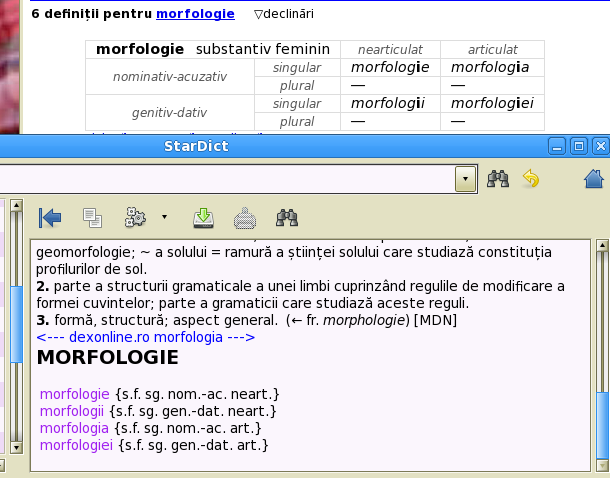
Note that it is possible to use the “Result” button (on the upper-left corner of the StarDict's GUI) to select the results from the morphological dictionary.
It is possible, of course, to enable or disable the morphological dictionary without affecting the display of information from the main dictionary.
The morphological dictionary uses lists of forms (with tags) - not tables. It uses colors for the differentiation of nouns, adjectives, verbs from the other classes of words.
When you click on a word in StarDict, you select it. Then press the middle button of the mouse and you jump to the article about the selected word.
You also may call the context menu (as shown in the “Usage” figure ■) and query.
When scan is enabled, a floating window appears and you may just consult that window (without jumping to the article about the selected word in the main panel).
StarDict has the possibility to show the search history (see the “Usage” figure ■).
There is also a button (between “Fuzzy Search” and “Home”) for an immediate “Go Back”. Use it to go back to the last search.
Working with the files from DEX online I fully realized the immense value of the tables (with definitions, lexems, word forms etc.) from DEX online.
StarDict is only a tool for convenient access to the corpus of definitions in electronic format. But the really valuable files are the sources of the dictionary.
Procedures similar to those discussed here could be used for building a variety of tools for the investigation of the Romanian language. Beyond the mundane use that is explained here in the usage section ■ there are interesting possibilities for research. Sadly, in our country, there is a reduced interest in humanistic computing.
The DEX online dictionary for StarDict is free software; Is is under the terms of the GNU General Public License. See also the conditions of the DEX online project. The dictionary is distributed in the hope that it will beuseful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See copyright-GPL.txt in the archive with the dictionary for details.
 .
.
The above archive contains Python and Bash scripts.
The license is GPL. See the sources for details.
For usage consult this note. The size of the archive with tools is 13.7 KB, but the space on disk required for their use is (on my computer) is about 1 GB. Thus you need at least 1 GB for using them. Make copies of all the sensitive files and use a special folder for processing. I would also say that - when resources are available - it would be more prudent to use a separate computer for experiments. Do not work on your laptop! I also think that the tools work (or work safely) only under GNU/Linux. Remember! There is NO WARRANTY.