On the computer that I use most of the time I have Fedora 7. Fedora includes GNU Aspell, but there is no RPM with a dictionary for Romanian.
The Internet is a very curious place. It took me quite a lot of time to realize that there is a project with excellent dictionaries for Romanian (including the dictionary for GNU Aspell). The name of the project is rospell.
The main effort, in the case of Rospell, seems to be in the direction of Open Office.
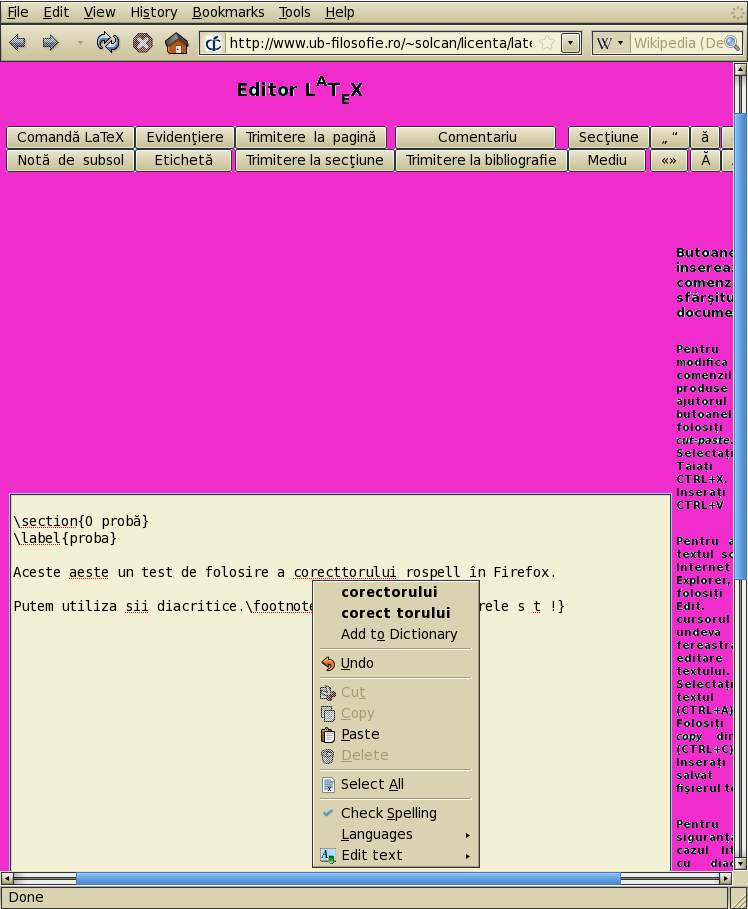
There is also the possibility to use the dictionary in Firefox.
The installation process for Aspell is quite simple. You have all the explanations on the Rospell site. I will only formulate here some comments that might be useful in the case of other languages too.
The rospell package is minimal. In fact, what you really need is the list of words. It has the name ro.cwl and it is a compressed file. If you want to see what is in the list, you have to uncompress it:
word-list-compress d < ro.cwl > ro.wl
The file ro.wl is quite big. It has more than 20MB.
There is no affix file for Aspell. There is one for Open Office, but not for Aspell. As I have said, it is a good illustration of a minimal system for a language.
The next file you are going to need is a file with extension dat. Normally, it is called ro.dat, but you may rename it. For example, you can call it rn.dat, if there is no name clash in the folder
/usr/lib/aspell-0.60
or a similar folder for other versions of GNU Aspell. The rospell installer detects this folder in the first part of the installation process. However, if you make changes there you should first consult the Aspell documentation. And take full responsibility for what you do!

Beyond the name of the language, there are some other key elements in the dat file. I had to specify, for example, the value of “soundslike”. The system, in my case, did not work without it.
You also have to pay attention to the encodings. I will come back later to this problem.
The encoding of the file ro.wl may be changed with iconv tool. It is also very easy to change the Romanian letters şŞţŢ from the cedilla version to the comma version and vice versa.
The rn.multi file just says:
add rn.rws
But you have to prepare the rn.rws file with the command:
aspell --lang rn create master ./rn.rws < ro.wl
Then you just copy in /usr/lib/aspell-0.60 (or the similar folder) three files: rn.dat, rn.multi and rn.rws (you need root privileges for that!).
When you check files with this installation of the rospell dictionary you issue a command like this:
aspell --lang rn -c test.txt
In my case, I kept open the possibility to use the ro files for an experiment. I keep the rospell dictionary for the normal work. I experiment with another list. The dictionary and the other files, in this case, are unfinished.
Now it is obvious why I use different names for the files. I do not want to break the working installation during the experiments.
They experimental files are under the GNU license. Anyone who has enough energy and the appropriate knowledge can hack the files, but has no right to hide the files or the modifications.
I will describe in the rest of this note the structure of the files and the way in which they can be used. You have to take full responsibility for what you do with the files. There is no implicit or explicit warranty.
If you want to spell check a text in a given language the first piece that you will need is a list of words. GNU Aspell does not use the word list as such. You need it however for making Aspell able to check the language.
In the case of Romanian, I named the files with the lists of words
ro-lista-cuvinte.wl
The list is extracted from the definitions in dexonline.ro. This puts automatically the list of words under the GNU license. Anyway, I think that it would be absurd from an ethical point of view to claim that the file with the list of words in a language is proprietary software.
In 2005, I worked with a list of words encoded according to ISO-8859-2.
In 2009, the list I use under Fedora 7 uses the UTF-8 encoding.
There is a special problem with the Romanian letters şŞţŢ. The correct version is with a comma under the respective letters. The form with a cedilla is however extremely widespread in electronic publications. For an extensive treatment of the whole topic - in Romanian - see the site secarica.ro.
The 2009 ro-lista-cuvinte.ro uses ş and ţ with a comma under the letter. However, as I will explain later, it is easy to adopt the other version of the letters. Of course, the simplest thing is to change the version of the four letters in the word list, but this is not enough.
In the case of Romanian, the affix file is named
ro_affix.dat
The term “affix” is misleading. This file is neither a list of affixes, nor of rules for the use of affixes. In fact, the file defines flags that are inserted in the word list.
In Romanian, a word like casă (house) has various forms:
casă caselor casele casei casa case
If you put in the word-list a flag like this:
casă/F
the GNU Aspell program looks into the affix file and expands the word-list according to the rule for the flag F in the ro_afix.dat file.
Thus, the affix file defines rules that enable the compression of the word-list. Instead of six forms for casă, we insert just one form with the appropriate flag.
A very important command in the affix file is
SET UTF-8
This command sets the encoding and has to agree with the data-encoding for the respective language.

The second and the third line are very important in this file. The first tells the system that the data are encoded according to UTF-8.
GNU-Aspell, in its internal processes, does not work with Unicode. It has to know how to handle the data in Unicode. In the case of Romanian, the rules are set in the iso8859-16 files (that you can find in GNU Aspell's library).
The iso8859-16 files are build according to the specifications in the “Additions for Romanian” of Unicode's Latin Extended-B. They work with the şŞţŢ Romanian letters with comma bellow.
You may ask if it is possible to work with the şŞţŢ Romanian letters with cedilla. Yes, it is. You have to change the version of the four letters in the word-list and in the affix-file. Then you have to modify the charset in the ro.dat file to iso8859-2.
The ro.multi file contains one line
add ro.rws
The ro.rws is the master file. I have not included it in the archives, because it is easy to build it locally.
In order to build the ro.rws file, open a command-line in the folder with the word-list, the affix and the ro.dat file. Issue the command
aspell --lang ro create master ./ro.rws < ro-lista-cuvinte.wl
This will create the ro.rws file in the current folder.
For the next operations you need root rights if GNU Aspell is not installed locally (in your home). In the case of the standard locations of GNU Aspell 0.60, the installation folder is
/usr/lib/aspell-0.60
You have to copy there the files
ro_affix.dat ro.dat ro.rws ro.multi
I do this with the GNU Midnight Commander. The MC opens in the terminal and works in text mode. It has two panels. In one panel I display the folder in which I have built ro.rws; in the other I display the /usr/lib/aspell-0.60 folder. Then I select and copy the specified files.
The four files, in /usr/lib/aspell-0.60, are owned by root. You must not forget to check if group and others can read those files. Without reading rights, you will not be able to check the spelling!
If you can  , you can watch a short movie which illustrates the use of GNU Aspell.
, you can watch a short movie which illustrates the use of GNU Aspell.
In the movie, I check the 00-test.tex. I tell GNU Aspell to use the Romanian dictionary:
aspell --lang ro -c 00-test.tex
The GNU Aspell interface starts in text mode. It splits the terminal's window in three parts: in the upper part is the text. In the middle GNU Aspell shows its suggestions. The last line is a command-line.
There two basic groups of operations: press numeric keys; press letter keys.
The numeric keys correspond to a correct form. You have to press the key which corresponds to the appropriate choice.
The letter keys, when pressed, start the execution of various operations.
If you press the i key, Aspell goes to the next word which seems wrong. If you press the a key, the word is added to the personal dictionary and Aspell goes to the next problematic word.
Now, GNU Aspell, by default, creates a back-up file. If you press the b key, Aspell exists and abandons all the changes.
The most problematic key is the r key. This opens the possibility to type the correct form of the word. At least with my Romanian keyboard, the edit process does not go well. I suggest to type some approximation of the correct word and let Aspell try again to guess the correct form. If it does, you can press the corresponding numeric key.
The rest of the operations in the text interface should be obvious.
You must, however, pay attention to the following fact: Aspell creates a back-up file, but you must rename it if you want to keep it after a new spell check. Aspell overwrites the old back-up file.
Sometimes it is easy to press the wrong numeric key. How could you review and repair, if it is the case, the changes? My solution is to use a program which can visualize the differences between files. With such a program it is easy to compare the corrected file and the back-up file.

In the test file all has gone well, except the word underlined in yellow. Aspell misses words starting with a s with cedilla (the incorrect form of the Romanian ş). Otherwise, in the middle of the word it gets it.
There are some important rules for the work with electronic texts.
The preliminary rule, I think, is to use reasonably long text files. If you write a book, do not put the whole book in one big file. The rule of thumb would be to put each chapter in a separate text file.
Another preliminary rule is to choose names for the files which order them and make their identification easy. For example, I have 60 items in a folder with notes on DjVu. The main one is djv.tex; the djv4.tex is a note on version 4 of the DjViewer and so on. All the files (archives, images etc.) connected with djv.tex start their name with djv and so on.
There are three basic rules of thumb for writing and rewriting a text:
First, write it in the logical form (my choice: LATEX ). Put every sentence on a different logical line. They will look like the premises of a logical inference. You will also be able to see if there is only one key-sentence in the paragraph. Then you can see if it is supported by the other sentences.
Second, check the spelling (my choice: GNU Aspell). Check the differences between the corrected file and the back-up file. See if you missed something.
Third, examine the text in a visual form. The visual form might be a dvi file, a pdf, an rtf or an html file, as seen in the respective viewer. The visual form will offer you a new perspective on the meaning of the text. Try to see if what you say makes sense. Go back to the logical phase of the work and rewrite the text.
I will not elaborate here on these rules. I want to emphasize only the fact that it is a bad idea to check a huge file. You might check the spelling of a chapter or of an article, but it would be difficult to check a big file.

The 2009-01-22 is similar to the last archive. I have cleaned the list of words (but there is still garbage in there!). I have experimented with the affix file. The affix file is built manually and tries to follow the logic of the Romanian grammar. I use the affix file when I add words to the list. A flag generates automatically all the other forms of the word. However, to do this manually is a tedious task. No wonder they use the munch tool instead.

The 2009-01-12 archive contains a word-list in UTF-8 encoding and with şŞţŢ with comma bellow. All the other files use a similar encoding and version of the Romanian letters. I tested it in Fedora 7. It should work on any UTF-8 enabled GNU/Linux system.

The 2005 version of the files uses the ISO-8859-2 encoding and şŞţŢ with cedilla. I tested it on Fedora 3 and 4 (GNU/Linux systems with UTF-8 enabled). I have also tested it on Win98SE. See my older notes on Romanian spelling.